
CSAPP 공부 - Lecture 01: Course Overview
인트로
책을 수업 노트로 생각하면 됨
코스 테마: 추상화는 좋지만 현실을 잊지는 말자
- 대다수의 컴퓨터 과학, 컴퓨터 공학 과목들은 추상화를 강조
- 추상 데이터 타입
- Asymptotic analysis
- 이러한 추상화는 한계가 있음
- 특히 버그
- 기저에 깔린 구현의 디테일을 이해할 필요가 있음
- 이 과목을 수강하여 얻을 수 있는 유용한 것들
- 효율적인 프로그래머가 된다
- 버그들을 효율적으로 찾아 제거할 수 있다
- 프로그램 성능을 이해하고 조절(tune)할 수 있다
- 컴퓨터 과학 및 전기컴퓨터공학에서의 “시스템” 과목에 대비한다
- 컴파일러, 운영체제, 네트워크, 컴퓨터 구조, 임베디드 시스템, 스토리지 시스템 등
- 효율적인 프로그래머가 된다
중요한 사실 #1: int는 정수가 아니며, float는 실수가 아니다
- 예시 1: $x^2\geq 1$은 참인가?
- float: 그렇다!
- int
- 40000 * 40000 = 1600000000
- 50000 * 50000 = ??
- 예시 2: $(x+y)+z=x+(y+z)$는 참인가?
- unsigned & signed: 그렇다!
- float
- (1e20 + -1e20) + 3.14 → 3.14
- 1e20 + (-1e20 + 3.14) → ??
직접 쉘에서 수식을 계산하면서 두 경우에 대한 예시를 보였다. 두 수 체계 모두 특이한 성질을 가지며 유한한 표현 범위를 가진다. int는 오버플로우가 생기고 float는 정밀도 손실이 발생한다.
컴퓨터 산수(Computer Arithmetic)
- 랜덤한 값을 생성하지 않음
- 산술 연산은 중요한 수학적 성질을 가짐
- 모든 “일반적인” 수학적 성질을 가정할 수 없음
- 유한한 범위의 표현 범위 때문
- 정수 연산은 “환(ring)” 성질을 가짐
- 교환법칙, 결합법칙, 분배법칙
- 부동소수점 연산은 “순서(ordering)” 성질을 가짐
- 단조성, 부호의 값
- 관찰
- 어떤 맥락에서 어떤 추상화가 적용되는지 이해하는 것이 필요
- 컴파일러 작성자와 고도의 신뢰성이 필요한 어플리케이션(serious application) 프로그래머에게는 중요한 문제
로켓을 컨트롤하는 등의 프로그램에서는 이러한 문제가 매우 중요하다. 유명한 취약점 사례로 양수만 들어올 것을 기대한 프로그램에 어떤 똑똑한 사람이 음수값을 던져서 시스템을 무효화하는 경우가 있다.
중요한 사실 #2: 어셈블리를 알아야한다
- 아마도 어셈블리로 프로그램을 짤 일은 없을 것
- 컴파일러가 당신보다 더 잘하고, 더 인내심 깊음
- 그러나, 어셈블리를 이해하는 것은 기계 수준 실행 모델의 핵심
- 버그 상황에서 프로그램의 동작
- 고수준 언어 모델들은 무너짐
- 프로그램 성능 최적화(tuning)
- 컴파일러에 의해 수행되는 최적화와 그렇지 않는 것을 이해
- 프로그램의 비효율성의 근원을 이해
- 멀웨어를 만들거나 멀웨어와 싸우기
- x86 어셈블리는 최고의 선택!
- 버그 상황에서 프로그램의 동작
기계 수준의 프로그래밍이란 컴퓨터에 의해 실질적으로 실행되는 명령어 텍스트 버전인 어셈블리와 실제 바이너리 레벨의 명령어인 오브젝트 코드 C로 작성한 코드가 어떻게 기계에서 실행되는가 이 과목은 어셈블리 코드를 C 컴파일러가 작성한 걸 토대로 이해 인텔 x86-64를 기반으로 학습 그 전에는 32비트 버전도 가르쳤는데 지금은 64비트만 다룸
중요한 사실 #3: 메모리는 중요하다. RAM은 비물리적 추상화다.
- 메모리는 무한하지 않음
- 반드시 할당되고 관리되어야 함
- 많은 응용 프로그램들이 메모리에 의해 성능이 결정됨(memory dominated)
- 메모리 참조 버그는 특히나 파괴적임(pernicious)
- 그 영향이 시간과 공간 모두에서 동떨어져 나타나기 때문
- 메모리 성능은 일정하지 않다(not uniform)
- 캐시와 가상메모리 효과가 프로그램 성능에 커다란 영향을 미칠 수 있음
- 프로그램을 메모리 시스템의 특성에 맞게 조정하면 유의미한 성능 향상으로 이어질 수 있음
메모리 참조 버그 예제
typedef struct {
int a[2];
double d;
} struct_t;
double fun(int i) {
volatile struct_t s;
s.d = 3.14;
s.a[i] = 1073741824; /* Possibly out of bounds */
return s.d;
}
- fun(0) → 3.14
- fun(1) → 3.14
- fun(2) → 3.1399998664856
- fun(3) → 2.00000061035156
- fun(4) → 3.14
-
fun(6) → Segmentaion fault
- 결과는 시스템에 따라 다름
- 설명:
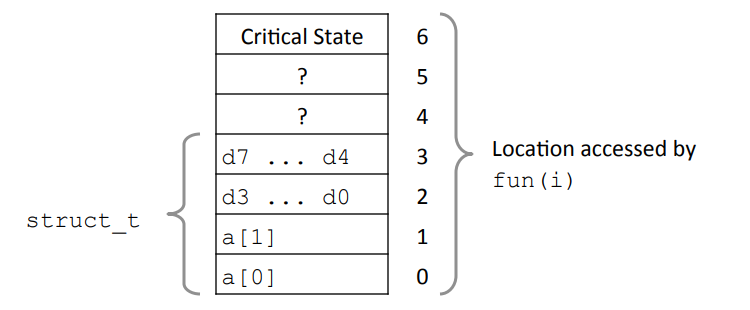
fun은 s.a[i]에 이상한 값을 넣음
i는 0 또는 1이어야 할 것
하지만 이상한 값을 시도해볼 수 있음
2를 넣으면 갑자기 a와 아무 상관없어 보이는 부동 소수점이 영향을 받음
3을 넣어도 마찬가지
6을 넣으면 크래시가 발생
뭔가 기이한 일이 일어난 것
이유는 데이터가 메모리에 어떻게 저장되고 어떻게 접근하는가와 관련이 있음
C/C++은 배열에 대한 범위 검사를 하지 않음, 아무 불만 없음
하지만 운영체제는 불만 있을지도
이 특정한 배치에서는 한 칸이 4바이트
만약 a[0], a[1]을 건드리는건 의도한 그대로 수정하는 것
하지만 그 이상에 접근하는 것은 d를 건드리게 됨
그러다가 인덱스 6에 도달하면 프로그램의 상태를 건드려버린 것
결국 프로그램 크래시를 발생시킴
- C와 C++은 어떠한 메모리 보호도 제공하지 않음
- 범위를 벗어난 배열 참조
- 유효하지 않은 포인터 값
- malloc/free의 잘못된 사용(오용, abuse)
- 끔찍한 버그로 이어질 수 있음
- 버그가 어떤 영향을 미칠지는 시스템과 컴파일러에 달려있음
- 원격 작용 (Action at a distance)
- 접근 중인 객체와 논리적으로 무관한 객체가 오염됨
- 버그의 영향은 버그가 생성된지 한참 후에야 처음으로 관찰될 수도 있음
- 어떻게 해결하는가?
- Java, Ruby, Python, ML, … 등으로 프로그램 작성하기
- 어떤 상호작용이 발생할 수 있는지 이해하기
- 참조 오류를 감지할 수 있는 도구를 사용하거나 개발하기 (예: Valgrind)
몇 시간에서 몇 주 동안은 잘 작동하다가 한참전에 오염된 데이터에 의해 버그가 발생할 수 있음 해결하기 매우 어려움
C/C++로 코드를 짜지 않을 정당한 이유가 된다는 것은 인정 하지만 경험이 쌓이면 직접 범위 체크를 하게 되고 문제를 방지할 수 있는 도구가 있음 그러니 반드시 언어를 바꿔야하는 건 아님
기계수준에서 자료구조가 어떻게 표현되는지 이해하는 것은 이런 맥락에서 매우 큰 차이를 만듦
중요한 사실 #4: 성능에는 점근적 복잡도 이상의 것이 있다
- 상수 계수도 중요하다!
- 정확한 연산 횟수를 세는 것 조차도 성능을 예상할 수 없다
- 코드를 어떻게 작성하느냐에 따라 10:1 수준의 성능 범위 차이를 쉽게 볼 수 있음
- 반드시 다양한 수준의 최적화를 해야함: 알고리즘, 데이터 표현, 프로시저, 루프
- 성능 최적화를 위해서는 반드시 시스템을 이해해야 한다
- 프로그램이 어떻게 컴파일되고 실행되는가
- 프로그램의 성능은 어떻게 측정하고, 병목 지점은 어떻게 식별하는가
- 어떻게 코드의 모듈성과 범용성을 해치지 않으면서 성능을 개선하는가
메모리 시스템 성능 비교

- 계층적 메모리 구조
- 성능은 접근 패턴에 따라 달라짐
- 다차원 배열을 순회하는 방법도 포함
2048 * 2048 배열을 src에서 dst로 복사하는 함수 유일하게 다른 점은 루프의 nested 구조 이 시스템에서는 20배 가량의 차이가 발생
왜 성능이 다른가
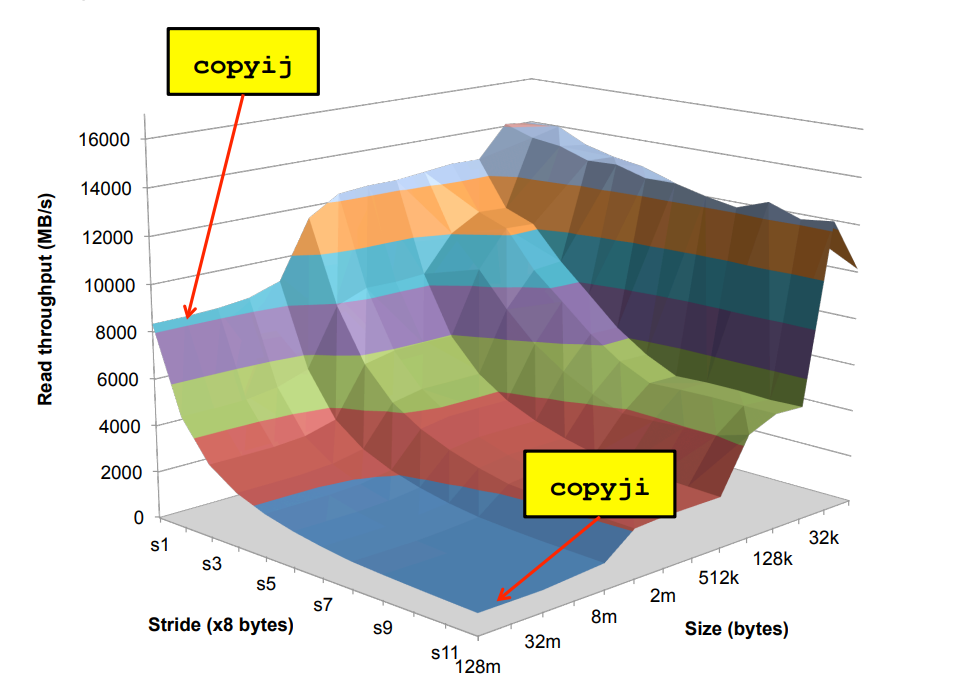
이를 이해하려면 책의 표지를 봐야 함(원서 표지에는 이 그림이 크게 그려져있음) 두 함수는 메모리 접근 패턴에서 다른 지점에 있음 행 순서로 접근하는게 열 순서로 접근하는 것보다 빠름 계층적 메모리 구조의 캐시메모리 때문에 한 쪽이 훨씬 더 빠른 것
중요한 사실 #5: 컴퓨터는 프로그램 실행 이상의 것을 한다
- 컴퓨터는 데이터를 안팎으로 실어날라야 함
- I/O 시스템은 프로그램의 신뢰성과 성능에 매우 중요
- 네트워크를 통해 상호간 소통함
- 많은 시스템 수준의 문제들은 네트워크가 존재할 때 발생함
- 자율적인(autonomous) 프로세스들에 의한 동시성 작업
- 신뢰할 수 없는 매체에 대처하기
- 크로스 플랫폼 호환성
- 복잡한 성능 문제
- 많은 시스템 수준의 문제들은 네트워크가 존재할 때 발생함
컴퓨터는 단순히 독립된 장치로서 작은 프로그램을 실행하는 것에서 그치지 않고 네트워크릍 통해 상호작용함
강의 관점
- 대부분의 시스템 강의들은 제작자 중심임
- 컴퓨터 구조
- Verilog를 통해 파이프라인 프로세서를 설계
- 운영체제
- 운영체제의 일부분을 예시로서 구현
- 컴파일러
- 간단한 언어를 위한 컴파일러를 제작
- 네트워크
- 네트워크 프로토콜을 구현하고 시뮬레이션
- 컴퓨터 구조
이러한 전형적인 강의들과 다름 어떻게 구현할지에 대한 것이 아님 프로그래머의 관점
강의 구성요소
- 강의
- 고수준의 개념
- 연습(Recitation)
- 응용된 개념들, 실습(Labs)을 위한 중요한 도구와 기술들, 강의 내용의 명확화(clarification), 시험범위
- 실습(Labs, 총 7개)
- 이 강의의 핵심
- 1-2주 소요
- 시스템 관점의 깊은 이해를 제공
- 프로그래밍과 측정을 수행
- 시험 (중간+ 기말)
- 개념 및 수학적 원리에 대한 이해도를 시험
Recitation은 TA(조교)들이랑 소규모로 그룹 지어서 수업과 관련된 내용 더 알아보는 시간임
간략한 강의 개요
프로그램과 데이터
- 주제
- 비트 연산, 산술, 어셈블리 언어 프로그램
- C 제어 및 데이터 구조의 표현
- 컴퓨터 구조와 컴파일러의 관점을 포함
- 과제
- L1 (datalab): 비트 조작
- L2 (bomblab): 이진수 폭탄 해체하기
- L3 (attacklab): 코드 주입 공격의 기초
메모리 계층
- 주제
- 메모리 기술, 메모리 계층, 캐시, 디스크, 지역성
- 컴퓨터 구조와 OS의 관점을 포함
- 과제
- L4 (cachelab): 캐시 시뮬레이터를 만들고 지역성 최적화
- 프로그램의 지역성을 활용하는 방법을 배움
- L4 (cachelab): 캐시 시뮬레이터를 만들고 지역성 최적화
예외적 제어 흐름
- 주제
- 하드웨어 예외, 프로세스, 프로세스 제어, 유닉스 시그널, 비지역 점프(nonlocal jumps)
- 컴파일러, OS, 컴퓨터 구조의 관점을 포함
- 과제
- L5 (tshlab): 자신만의 Unix 쉘을 개발
- 동시성에 대한 첫 입문
- L5 (tshlab): 자신만의 Unix 쉘을 개발
가상 메모리
- 주제
- 가상 메모리, 주소 번역, 동적 저장소 할당
- 컴퓨터 구조와 OS의 관점을 포함
- 과제
- L6 (malloclab): 자신만의 malloc 패키지를 개발
- 시스템 수준 프로그래밍에 대한 실질적인 느낌 얻기
- L6 (malloclab): 자신만의 malloc 패키지를 개발
네트워크와 동시성
- 주제
- 고수준 및 저수준 I/O, 네트워크 프로그래밍
- 인터넷 서비스, 웹 서버
- 동시성, 동시성 서버 설계, 스레드
- select를 통한 I/O 멀티플렉싱
- 네트워크, OS, 컴퓨터 구조의 관점을 포함
- 과제
- L7 (proxylab): 자신만의 웹 프록시를 개발
- 네트워크 프로그래밍과 동시성 및 동기화에 대한 심화 학습
- L7 (proxylab): 자신만의 웹 프록시를 개발
댓글남기기