
CSAPP 공부 - Lecture 02:Bits, Bytes, and Integers
모든 것은 비트다
- 각 비트는 0 또는 1임
- 비트의 집합을 다양한 방식으로 인코딩하고 해석함으로써
- 컴퓨터는 무엇을 할지 결정함(명령어)
- 그리고 수, 집합, 문자열 등을 표현하고 조작(manipulate)함
- 왜 비트인가? 전자적 구현
- 쌍안정 소자(bistable elements)에 저장하기 쉬움
- noisy하고 부정확한 전선에서 신뢰성있게 전송될 수 있음
인간은 10개의 손가락과 발가락 가지고, 10진수를 사용한다. 최초의 컴퓨터 애니악도 10진수였는데, 그러다가 2진수를 고안해낸다.
디지털 세상에서는 아날로그 신호와 달리 낮은 전압을 0으로 부르고 높은 전압을 1로 부를 수 있다. 노이즈, 회로의 결함(imperfection) 등이 들어와도 threshold 안에만 들어오면 깔끔하게 해석할 수 있다.
예를 들어, 2진수에서 수를 셀 수 있다
- 2진수 표현
- $15213{10}$을 $11101101101101{2}$로 표현할 수 있음
- $1.20{10}$을 $1.0011001100110011[0011]…{2}$로 표현할 수 있음
- $1.5213\times10^4$을 $1.1101101101101_{2}\times2^{13}$로 표현할 수 있음
바이트 값을 인코딩하기
- 1 바이트 = 8 비트
- 2진수: $00000000{2}$ 부터 $11111111{2}$까지
- 10진수: $0{10}$ 부터 $255{10}$까지
- 16진수: $00{16}$ 부터 $\text{FF}{16}$까지
- ‘0’부터 ‘9’, ‘A’부터 ‘F’까지 문자를 사용
- C에서 FA1D37B은 아래와 같이 쓸 수 있음
- 0xFA1D37B
- 0xfa1d37b
수를 32비트 혹은 64비트로 나타내는 것은 성가신 일이다. 그래서 보통 4개의 비트를 묶어 16진수로 나타낸다. 10에서 15는 A에서 F로 표현한다.
16진수를 보다보면 2진수로 쉽게 변환할 수 있다.
| bin | hex |
|---|---|
| 1111 | f |
| 1100 | c |
| 1010 | a |
일단 이렇게 외워두면 b, d, e는 중간을 보간해서 생각하낼 수 있다(0에서 9는 별 어려움 없이 할 수 있다).
데이터 표현 예시
| C 자료형 | 일반적인 32비트 | 일반적인 64비트 | x86-64 |
|---|---|---|---|
| char | 1 | 1 | 1 |
| short | 2 | 2 | 2 |
| int | 4 | 4 | 4 |
| long | 4 | 8 | 8 |
| float | 4 | 4 | 4 |
| double | 8 | 8 | 8 |
| long double | - | - | 10/16 |
| 포인터 | 4 | 8 | 8 |
참고로 인텔 머신에는 애매하게도 10바이트(80비트)짜리 부동소수점 표현이 있다. 64비트 머신에서는 16바이트로 정렬하기 때문에 6바이트가 낭비된다.
불 대수
- 19세기 조지 불에 의해 개발됨
- 논리의 대수적 표현
- “참”을 1로, “거짓”을 0으로 인코딩
- 논리의 대수적 표현
- AND
- A = 1이고 B = 1일 때 A & B = 1
- OR
- A = 1이거나 B = 1일 때 A | B = 1
- NOT
- A = 0일 때 ~A = 1
- Exclusive-OR(XOR)
- A = 1이거나 B = 1이지만, 둘 다 1은 아닐 때 A ^ B = 1
일반적인 불 대수
- 비트 벡터에 대하여 연산
- 연산은 비트 단위로 적용됨

- 연산은 비트 단위로 적용됨
- 불 대수의 모든 속성이 적용됨
이러한 연산을 비트 벡터에 대해서도 할 수 있다. 연산은 비트 단위로 적용되며, C에서 제공하는 저수준의 기능이기도 하다.
예시: 집합을 표현하고 조작하기
- 표현
- w 비트의 너비를 갖는 벡터는 ${0,\dots,w-1}$의 부분집합을 나타낼 수 있음
- $a_{j}=1\ \text{if}\ j\in a$
- 01101001 → {0, 3, 5, 6}
- 76543210
- 01010101 → {0, 2, 4, 6}
- 76543210
- 연산
- & : 교집합(Intersection)
- | : 합집합(Union)
- ^ : 대칭차집합(Symmetric difference)
- ~ : 여집합(Complement)
불 연산을 집합을 표현할 때 사용할 수 있다. 1바이트는 0부터 7까지 8개의 수를 표현하기에 충분하므로, 각 비트로 8개의 수가 포함되었는지 여부를 표현할 수 있다.
AND 연산은 교집합(intersection), OR 연산은 합집합(union), XOR 연산은 대칭차집합(symmetric difference) NOT 연산은 여집합(complement)으로 구현된다.
이러한 연산은 매우 흔하다. 예를 들어, (라이브러리 호출 뒤에 숨겨져있지만) 파일 입출력에서 플래그를 적용할 때 사용된다.
C에서의 비트수준 연산
- &, |, ~, ^ 연산은 C에서 사용가능
- 모든 정수 데이터 타입에 적용
long,int,short,char,unsigned
- 인자를 비트 벡터로 간주
- 연산은 비트 단위로 적용됨
- 모든 정수 데이터 타입에 적용
- 예시 (char형)
- ~0x41 → 0xBE
- ~01000001 → 10111110
- ~0x00 → 0xFF
- ~00000000 → 11111111
- 0x69 & 0x55 → 0x41
- 01101001 & 01010101 → 01000001
- 0x69 | 0x55 → 0x7D
- 01101001 | 01010101 → 01111101
- ~0x41 → 0xBE
대조: C에서의 논리 연산
- 논리 연산자와 대조
- &&, ||, !
- 0을 “거짓”으로 간주
- 0이 아닌 모든 것을 “참”으로 간주
- 항상 0 또는 1을 리턴
- 단락 평가(Early termination)
- &&, ||, !
- 예시 (char형)
- !0x41 → 0x00
- !0x00 → 0x01
- !!0x41 → 0x01
- 0x69 && 0x55 → 0x01
- 0x69 || 0x55 → 0x01
- p && *p → 널포인터 접근 방지
&, | 한 개 짜리와 두 개 짜리를 헷갈리지 말 것, ~와 !도 마찬가지다.
논리 연산자는 Early Termination을 제공한다. 이를 통해 널 포인터 접근을 방지할 수 있다.
p && *p에서 p가 null이라면 0일테니 더 이상의 평가를 진행하지 않는 원리다.
시프트 연산
- 왼쪽 시프트:
x << y- 비트 벡터 x를 왼쪽으로 y만큼 시프트
- 왼쪽에 있던 여분의 비트는 날려버림
- 오른쪽은 0으로 채움
- 비트 벡터 x를 왼쪽으로 y만큼 시프트
- 오른쪽 시프트:
x >> y- 비트 벡터 x를 오른쪽으로 y만큼 시프트
- 오른쪽에 있던 여분의 비트는 날려버림
- 논리적 시프트(Logical shift)
- 왼쪽에 0을 채움
- 산술적 시프트(Arithmetic shift)
- 왼쪽에 MSB를 복제(replicate)함
- 비트 벡터 x를 오른쪽으로 y만큼 시프트
- 정의되지 않은 동작 (Undefined Behavior)
- 시프트 하는 양이 음수이거나 워드 크기 이상일 경우
왼쪽 쉬프트는 항상 같은데 오른쪽 쉬프트는 두 가지 옵션이 있다. 왼쪽에 0을 채우는게 logical shfit, 기존 값의 MSB를 복사하는게 Arithmetic shift이다.
shift 양이 음수거나 워드 크기 이상이면 UB이다.
예를 들어, x가 1바이트일 때 x << 8을 하면 어떤 결과가 나올까? 0이 나오는게 논리적인 추측에 맞다. 그러나 대부분의 머신에서는 x가 그대로 나온다. shift하는 수에 mod 8를 하기 때문이다. 즉, 하위 3비트만 보고 나머지는 무시한다.
어떤 머신은 실제로 0이 나올 수도 있고 위와 같이 그대로 x가 나올 수도 있는데, C에서는 아무것도 보장하지 않는다.
정수 인코딩하기
- Unsigned
- $B2U(X)=\sum^{w-1}{i=0}x{i}\cdot_{2}^i$
- B2U: Bit-level representation to an unsigned number (또는 Binary To Unsigned)
- Two’s Complement
- $B2T(X)=-x_{w-1}\cdot2^{w-1}+\sum^{w-2}{i=0}x{i}\cdot_{2}^i$
- B2T: Bit-level representation to an two’s complement number (또는 Binary To Two’s complement)
- $-x_{w-1}$: Sign Bit
short int x = 15213; short int y = -15213;
- C에서
short는 2바이트를 차지
| decimal | Hex | Binary | |
|---|---|---|---|
| x | 15213 | 3B 6D | 00111011 01101101 |
| y | -15213 | C4 93 | 11000100 10010011 |
- 부호 비트
- 2의 보수에서 MSB는 부호를 의미
- 양수는 0
- 음수는 1
- 2의 보수에서 MSB는 부호를 의미
2의 보수에서 음수를 표현할 때, 부호 비트를 통해 음수 가중치를 부여하는 것이 매우 중요한 아이디어이다.
B2U
| $i$ | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|
| $2^i$ | 16 | 8 | 4 | 2 | 1 |
| $x$ | 1 | 0 | 1 | 1 | 0 |
$x = 10110_2 = 16 + 4 + 2 = 22$ 여기서부호 있는 수는 MSB 하나의 차이
B2T
| $i$ | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|
| $2^i$ | -16 | 8 | 4 | 2 | 1 |
| $x$ | 1 | 0 | 1 | 1 | 0 |
$x = 10110_2 = -16 + 4 + 2 = -10$ 같은 비트패턴인데 어떻게 해석하느냐에 따라 달라졌다. 두 수식이 말하는건 이게 전부다.
MSB가 1이면 음수가 되니 부호비트라고도 하는 것이다.
수의 범위
- Unsigned 값
- UMin = $0$
- 000…0
- UMax = $2^w-1$
- 111…1
- UMin = $0$
- 2의 보수 값
- TMin = $-2^{w-1}$
- 100…0
- TMax= $2^{w-1}-1$
- 011…1
- TMin = $-2^{w-1}$
- 그 외
- -1
- 111…1
- -1
- $w=16$일 때 값
| Decimal | Hex | Binary | |
|---|---|---|---|
| UMax | 65535 | FF FF | 11111111 11111111 |
| TMax | 32767 | 7F FF | 01111111 11111111 |
| TMin | -32768 | 80 00 | 10000000 00000000 |
| -1 | -1 | FF FF | 11111111 11111111 |
| 0 | 0 | 00 00 | 00000000 00000000 |
unsigned 수의 범위는? 00000이면 0 11111이면 16+8+4+2+1=31 2의 보수의 경우 10000 = -16 → 가장 작은 수 01111 = 8 + 4 + 2 + 1 = 15 → 가장 큰 수
각각을 UMin, UMax, TMin, TMax라고 하자. 우리는 지금 워드 크기를 5로 잡았다.
UMax는 32에 아주 가깝다. $2^5-1$, 일반화해서 말하면 $2^w -1$ 비슷하게 TMin은 $-2^4$이므로 일반화해서 말하면 $-2^{w-1}$ TMax는 연속된 1들의 왼쪽 비트 보다 1 작다. $2^{w-1}-1$ 이러한 관찰을 통해 공식을 만들었는데, 이렇게 작은 예시를 생각하면 외우지 않고도 식을 세울 수 있다.
모든 비트가 1이면? 11111 = -16+8+4+2+1 = -1 모두 1인 비트패턴은 항상 -1이다.
2의 보수는 부호있는 수를 표현하는 유일한 방법은 아니지만, 매우 일반적인 방법이다.
워드 크기에 따른 값들
- 관찰
- |TMin| = TMax + 1
- 비대칭적 범위 (asymmetric range)
- UMax = 2 * TMax + 1
- |TMin| = TMax + 1
- C 프로그래밍
#include<limits.h>- 상수로 선언돼있음, 예를 들면
ULONG_MAXLONG_MAXLONG_MIN
- 값들은 플랫폼에 따라 다름(platform specific)
Unsigned & Signed 값 범위
- Equvalence
- 양수 값에 대해서는 인코딩이 동일함
- Uniqueness
- 모든 비트 패턴은 고유한 정수 값을 표현함
- 표현 가능한 각 정수는 고유한 비트 인코딩을 가짐
- ⇒ 역함수 매핑 가능
- $\text{U2B(}x)$ = $\text{B2U}^{-1}(x)$
- unsigned 정수에 대한 비트패턴
- $\text{T2B(}x)$ = $\text{B2T}^{-1}(x)$
- 2의 보수 정수에 대한 비트패턴
- $\text{U2B(}x)$ = $\text{B2U}^{-1}(x)$
| X (비트 패턴) | B2U(X) (Unsigned) | B2T(X) (Signed) |
|---|---|---|
| 0000 | 0 | 0 |
| 0001 | 1 | 1 |
| 0010 | 2 | 2 |
| 0011 | 3 | 3 |
| 0100 | 4 | 4 |
| 0101 | 5 | 5 |
| 0110 | 6 | 6 |
| 0111 | 7 | 7 |
| 1000 | 8 | -8 |
| 1001 | 9 | -7 |
| 1010 | 10 | -6 |
| 1011 | 11 | -5 |
| 1100 | 12 | -4 |
| 1101 | 13 | -3 |
| 1110 | 14 | -2 |
| 1111 | 15 | -1 |
흥미로운 특징: 비트패턴이 같아도 값이 달라지는 경우가 있다. 그 관계는 매우 간단하다.
2진수 11111을 unsigned로 해석하면 31이고, 2의 보수로 해석하면 -1이다. 여기서 해석하는 관점의 차이는 가장 왼쪽 비트가 16이냐 -16이냐의 차이이므로, 두 해석의 결과는 32만큼 차이난다. 달리 말하면 → $2^5$, $2^\text{워드크기}$만큼 차이난다. 이러한 관계는 중요하다.
표는 4비트에서 가능한 모든 수를 나열한 것이다. 부호비트가 0이면 같고 1이면 16만큼 차이난다.
모든 비트 패턴은 고유한 정수 값을 표현하고, 표현 가능한 모든 정수 값은 고유한 비트 인코딩을 가지므로 역함수로 대응(매핑)가능하다.
Signed & Unsigned 매핑
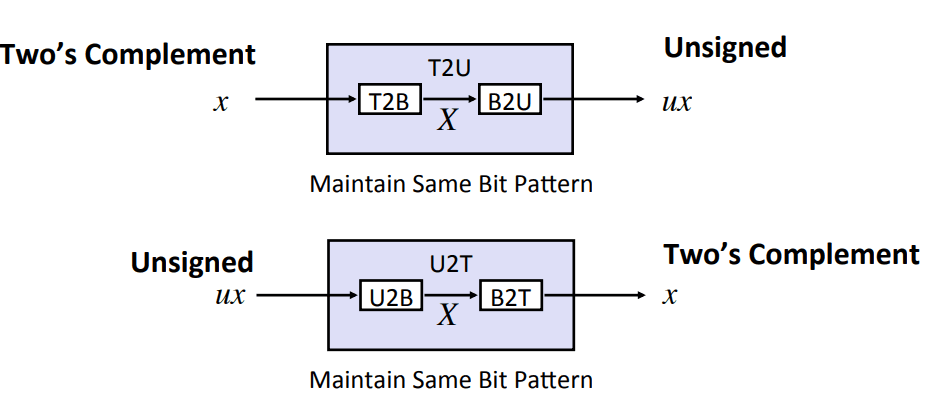
- unsigned와 2’s complement 사이의 대응: 비트 표현은 유지하고 재해석(reinterpret)
컴퓨터는 비트패턴 자체로 2’s complement인지 unsigned인지 알 수 없다.
Signed ↔ Unsigned 매핑
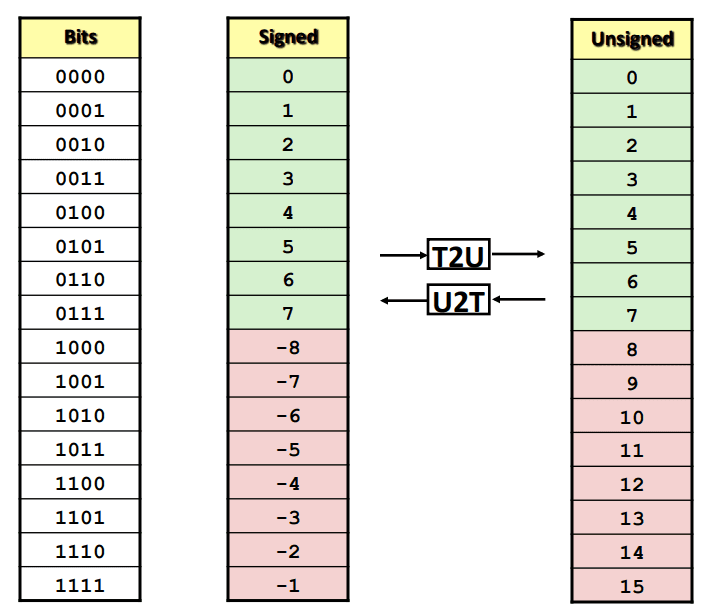
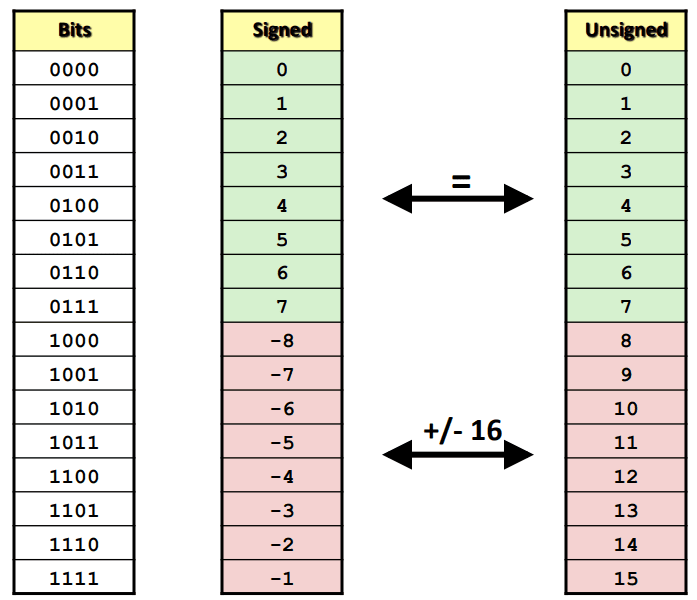
$\pm2^\text{워드크기}$만큼 차이남
Singed와 Unsigned간의 관계
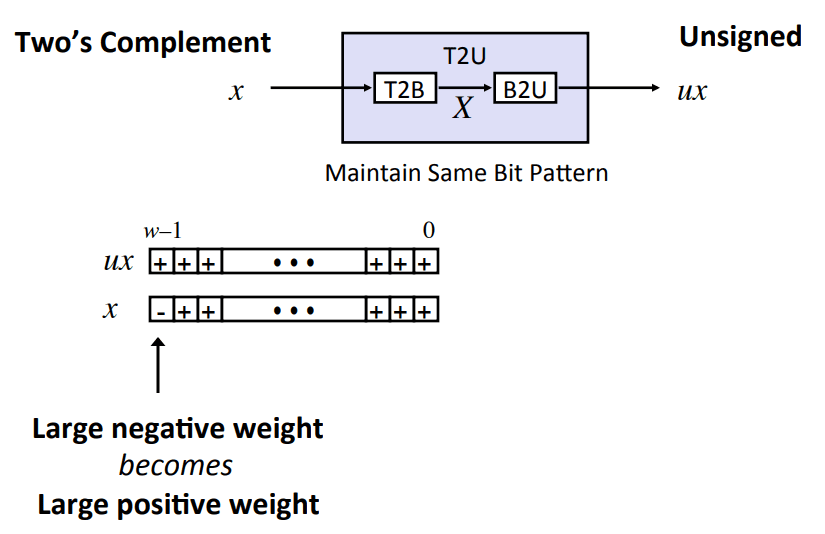
- 큰 음수 가중치가 큰 양수 가중치가 된다.
변환 시각화
- 2의 보수 → Unsigned
- 순서 역전
- 음수 → 큰 양수
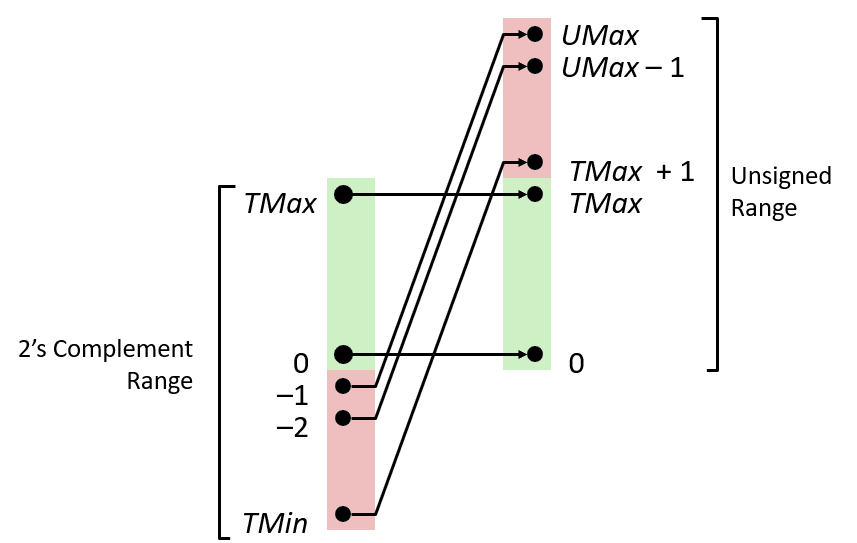
- 이것은 함수로 생각할 수 있음
- 양수 범위는 그대로 옮겨질 것이고 음수 범위는 위로 올라옴
- 이미지에서 보여주는 내용이 이것
C에서의 Signed vs Unsigned
- 상수
- 기본적으로 signed int로 간주됨
- “U”를 접미사로 가지면 unsigned
- 0U, 2494967259U
- 캐스팅
- 부호 있는 수와 부호 없는 수 간의 명시적 캐스팅은 U2T와 T2U와 동일하게 동작
int tx, ty; unsigned ux, uy; tx = (int) ux; uy = (unsigned) ty; - 대입과 함수 호출에 의해서도 암시적 형변환이 발생
tx = ux; uy = ty;
- 부호 있는 수와 부호 없는 수 간의 명시적 캐스팅은 U2T와 T2U와 동일하게 동작
이게 왜 중요한가? 파이썬 혹은 자바를 사용하면 문제가 잘 드러나지 않는다. C는 unsigned 자료형이 명시적으로 드러나는 몇 안되는 언어 중 하나이다.
캐스팅의 놀라움
- 표현식 평가
- 만약 unsigned와 signed가 단일 표현식에 섞여있다면, signed 값이 unsigned로 암시적 형변환 됨
- <. >, ==, <=, >=와 같은 비교 연산자 포함
- $W=32$인 경우의 예: TMIN = -2,147,483,648, TMAX = 2,147,483,647
| Constant1 | Constant2 | Relation | Evaluation |
|---|---|---|---|
| 0 | 0U | == | unsigned |
| -1 | 0 | < | signed |
| -1 | 0U | > | unsigned |
| 2147483647 | -2147483647-1 | > | signed |
| 2147483647U | -2147483647-1 | < | unsigned |
| -1 | -2 | > | signed |
| (unsigned) -1 | -2 | > | unsigned |
| 2147483647 | 2147483648U | < | unsigned |
| 2147483647 | (int) 2147483648U | > | signed |
사람들이 종종 실수하는 것: 2의 보수로 선언한 수와 unsigned로 선언한 수 사이의 캐스팅
어떤 연산이든 두 수 사이의 연산이 있을 때 signed 값은 묵시적으로 unsigned로 변환된다. 둘 중 하나가 unsigned면 signed로 변환되는 것이다.
0과 0U를 비교한다고 하면 unsigned로 평가된다. -1과 0U를 비교하면 unsigned로 평가되므로 -1이 더 크다.
TMax32 > TMin32 UMax32 < TMin32 |TMAX| = |TMIN|-1, 표현 범위를 절반씩 가져가는데 중간에 0이 있기 때문에 1만큼 차이나는 것
이러한 비대칭성이 끝없는 고통을 선사한다. 절댓값을 반환하는 예를 생각해보자.
if (x < 0)
return -x;
else
return x;
TMIN에 대한 리턴값은 (예상과 달리) TMIN이 될 것이다.
또 다른 예: 배열을 역순으로 순회하는 것을 상상해보자.
unsigned i;
for(i = n - 1; i >= 0; i--)
f(a[i]);
무한 루프를 돌게 된다. i가 0에서 UMax가 되기 때문이다. i는 unsigned니까 항상 0 이상일 수 밖에 없다.
조금 달리해서 이런 경우도 살펴보자.
int i;
for(i = n - 1; i - sizeof(char) >= 0; i++)
f(a[i]);
이것도 무한 루프를 돌게된다. sizeof는 unsigned 값을 반환(함수는 아니지만 어쨌든)하는데, 그러면 결국 unsigned 값 비교가 되기 때문이다.
Signed ↔ Unsigned 캐스팅 요약: 기본 규칙
- 비트 패턴은 유지된다.
- 그러나 재해석된다.
- $2^w$를 더하거나 빼는 것과 같은 예기치 못한 작용이 발생할 수 있다
- signed와 unsigned int를 포함하는 표현식
- int가 unsigned로 캐스팅된다!!
부호 확장
- 작업:
- w비트 signed int x가 주어짐
- 이것을 같은 값을 갖는 w+k비트 정수로 변환함
- 규칙:
- 부호 비트를 k개 복사함
- $X’=x_{w-1},\dots,x_{w-1},x_{w-1},x_{w-2},\dots,x_{0}$
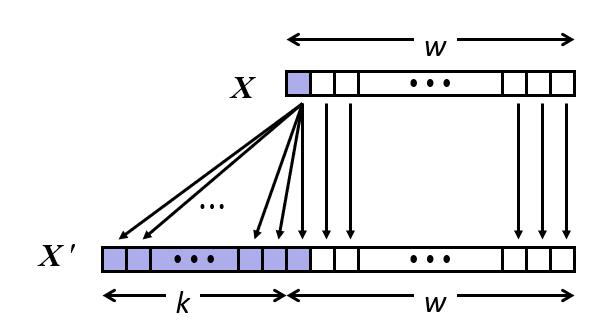
4비트 값을 생각해보자: 0110 이것을 5비트로 확장하려면 앞에 0만 추가하면 된다.
한편, 부호비트가 있는 1110을 생각해보자, 값은 -2이다. 이것을 5비트로 확장하려면 그대로 1110을 가져오고 앞에 부호비트 1을 붙이면 된다. 11110 = -16 + 8 + 4 + 2 = -2 원래 -8 역할을 했던 비트가 +8이 되고, 왼쪽에 새로 추가된 부호비트는 -16이므로 아무런 변화가 생기지 않는 것이다. 이것이 부호 확장의 아이디어이다.
반대로 버림(truncation)은? unsigned의 예를 들어보자 11011 = 16 + 8 + 2 + 1 = 27 1011 = 8 + 2 + 1 = 11 비트를 하나 떼내니까 $2^{n}$ 만큼 mod한 것으로 볼 수 있다. 27 mod 16 = 11, 여기서 $n$은 truncation 결과의 비트 수이다.
unsigned에 대한 모듈러 연산은 이해하기 쉽지만, 2의 보수의 경우는 그렇지 않다. 이번에는 2의 보수로서 11011을 보자. 11011=-16+8+2+1=-5 1011 = -8+2+1=-5 왜 같을까? 이건 결국 부호 확장과 동일하기 때문이다.
10011은? 10011=-16+2+1=-13 0011=2+1=3
unsigned와 비슷하게 적용해서 19 mod 16 = 3이 된다. 2의 보수로 해석했을 뿐 기본적으로는 19이므로 19로 해석한 것이다. 이 경우는 논리적이라고 느낄만한 산술적 특징은 아니다.
댓글남기기